
20240205_cluster_specific_optimization.md 14 KB
Cluster-specific optimization
- Associated:
The Problem
Optimizer changes are tricky to implement and deploy in a robust and predictable manner. The main problem is depicted by the following diagram.
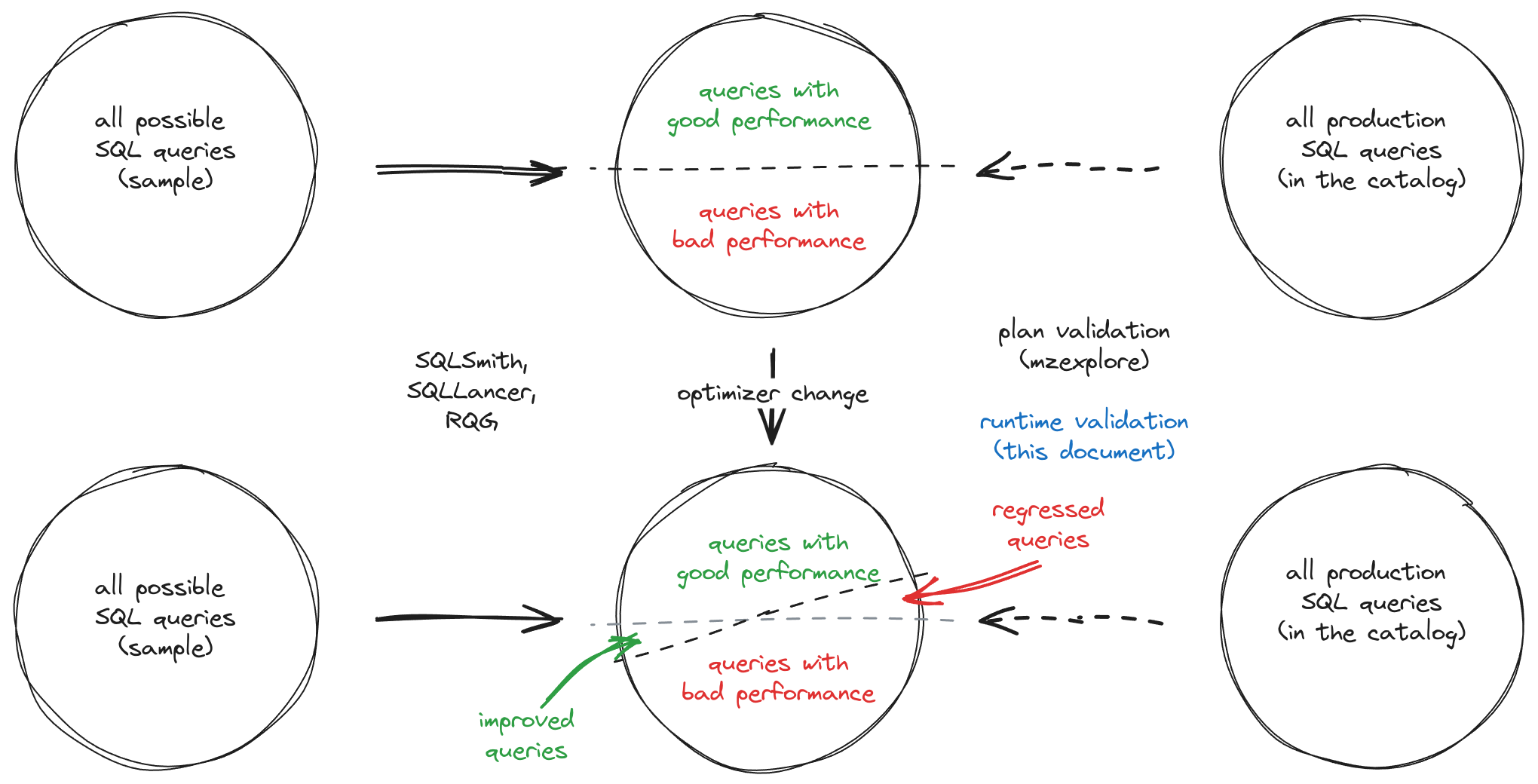
Most of the time, a change to our optimizer will not only improve the performance of some SQL queries (hopefully a majority), but also introduce performance regressions to others.
The expected plan regressions and improvements of an optimizer change in
general can be identified by running random query workloads using one of the
fuzzers available in our CI pipeline (RQG, SQLSmith, SQLLancer). However, we
currently lack the right tooling to determine the specific impact of such
changes to our current production environments.
The latter is of particular practical importance when prototyping and validating possible optimizer changes behind a feature flag:
- It will help us to quickly get a feeling of the potential improvements that our customers will see. This in turn can help us determine whether it is worthwhile to invest the necessary time to make the change production-ready.
- It will help us to identify potential performance regressions that will be observed by our customers once we roll out the change. This in turn can help us to improve the robustness of our rollout strategy for optimizer changes.
There are two dimensions of assessing the quality of SQL queries in production:
- Assessing the quality of the optimized plans. To a large extent this is
already supported with the introduction of the
mzexploretool (MaterializeInc/materialize#22892) and with adding the ability to control optimizer feature flags using theEXPLAIN WITH(...)syntax (MaterializeInc/materialize#22744). There are some known issues with the current state of the code, but we have fixes for those that should be merged soon (pending review). - Assessing the quality of the running dataflows. This is needed because sometimes the impact of an optimizer change is not directly evident in the optimized plan. Instead, we need to deploy and run the modified dataflow and compare its performance against its current version.
The current document proposes tooling and workflows in aid of (2).
Success Criteria
Members of the compute team have agreed upon the developed the minimal amount of tooling and code infrastructure required to enable the evaluation of proposed optimizer changes in production.
The new feature has been used to asses the potential impact of the following optimizer changes:
Out of Scope
Things that will be nice to have, but are intentionally left out of scope from the current proposal are listed below with a brief motivation for that decision.
- Not requiring
mz_systemaccess in order to do a runtime validation experiment. This doesn't seem urgent because we will always usemzexploreto first identify a small set of candidate dataflows. For those, we will in turn run a dedicated experiment together with a designated engineer that can temporarily requestmz_systemprivileges with Teleport (similar to thelgallocexperiments). - Provide tooling to automatically duplicate dataflow-backed catalog items from a reference cluster to a temporary cluster used to run an experiment. While this might be very helpful in general, we believe that most of our customers deploy their DDL statements with a script. For the first iteration of this feature it should be therefore sufficient to ask them to run a modified version of this script (with changed catalog item names) against the temporary cluster while running our experiments.
- Support experimentation on unmanaged clusters. Extending the syntax for
managed clusters should be sufficient for an MVP. Since the clusters will be
short-lived it doesn't make a huge difference which syntax the Materialize
employees will use to create them. Adding
FEATURESsupport for unmanaged clusters will require more code changes. Since the syntax is now deprecated, there is no need to additionally complicate this code. - Support changes of
CLUSTER-specific features withALTER CLUSTER. For the same reasons as above—for experimentation purposes we only need short-lived clusters.
Solution Proposal
The suggested high-level workflow for assessing the potential impact of an optimizer feature will be:
- Use
bin/mzexploreto identify dataflows and clusters that might be affected by an optimizer change gated behind a feature flag. - For each such cluster, run the following experiment:
The suggested workflow for running an experiment on a specific customer environment will be:
- Obtain
mz_systemprivileges through Teleport. - Create a dedicated cluster for the experiment. Use the feature flag to
enable the tested feature in the
CREATE CLUSTERdefinition. - Create an
UNBILLEDreplica for that cluster. - Ask the customer to replicate (a subset of) dataflow-backed catalog items defined on the original cluster to the experiment cluster.
- Monitor and record observed differences between the dataflows running in the original cluster and the (modified) dataflows running in the experiment cluster.
In order to facilitate this workflow, we propose the following changes (discussed in detail below):
- Extensions to the
CREATE CLUSTERsyntax. - Extensions to the optimizer API.
Extensions to the CREATE CLUSTER syntax
Extend the CREATE CLUSTER SYNTAX for managed cluster plans as follows:
CREATE CLUSTER <name> ... FEATURES (...)
The newly added FEATURES clause will be only visible by mz_system. We will
extend CreateClusterManagedPlan and CreateClusterManaged with a new
ClusterFeatures struct that models the feature flag configuration that can be
overridden on a per-cluster level.
Extensions to the optimize API
Here we can benefit from the unified optimizer interface introduced with
MaterializeInc/materialize#20569. As part of the associated changes we
introduced an mz_adapter::optimize::OptimizerConfig struct that currently can
can already be configured in a layered way:
- A top layer of settings bound from
SystemVars. - A layer of
EXPLAIN-specific overrides bound from theExplainContext, which is available when theCoordinatormethods that drive the optimization process are initiated fromsequence_explain_plan.
Since all Optimizer::new(...) constructor calls in the Coordinator happen at
a time where the target cluster for the optimized statement is already resolved,
we can just add a new layer for cluster-specific overrides between (1) and (2).
Minimal Viable Prototype
An sketch of the proposed design can be found in the MVP draft PR[^3].
Nothing is done yet, but once we agree on the SQL extensions the changes to get something working end-to-end should be done quite quickly.
Alternatives
Managing cluster-specific parameters with LaunchDarkly
There is prior art for this in PostgreSQL: you can set (most) system parameters at the database level, and they take precedence in order of:
system < database < role < session
or something lke that. If we get more use cases for such layering we can invest
the time to teach the SystemVars about cluster-specific parameters. Once we do
that, we should be able to enable feature flags on a per-cluster basis through
LaunchDarkly.
The approach is rejected (for now) because it requires more substantial changes
to the current state of our LaunchDarkly setup in main. Basically at the
moment we pull parameters from LaunchDarkly in a loop using a fixed
ld::Context[^1] that consists of:
- A context of
kind = environmentthat models the current Materialize environment. - A context of
kind = organizationthat models the environment owner.
If we want to provide cluster-specific configuration through LaunchDarkly, we
would need to extend the system_parameter_sync loop[^2] to run a
frontend.pull(...) call with a different ld::Context for each cluster. We
would then use the CLUSTER-specific ALTER SYSTEM extensions in SystemVars
in the backend.push(...) call.
Open questions
N/A
Future work
From @benesch:
As future work, it seems like it'd also be interesting to allow users to use the
FEATURESflag, limited to a restricted set of features that are worth allowing users to control.We might also consider introducing
CREATE TEMPORARY CLUSTER ... FEATURES(...)and limit certain features for use only in temporary clusters. These clusters would only last for a single SQL session, and therefore wouldn't survive an
envdrestart, and therefore wouldn't prevent us from removing the feature flag in a future version of Materialize.
Automatically duplicate dataflow-backed catalog items for experimentation
[^1]: ld_ctx definition
[^2]: system_parameter_sync definition
[^3]: MVP sketch (draft PR)